Lista korpusów
Smyrna to prosty konkordancer obsługujący język polski. Pozwala na łatwe przeszukiwanie i przeprowadzanie prostych analiz statystycznych na zbiorach tekstów w języku polskim, tzw. korpusach.
Smyrna obsługuje metadane. Oznacza to, że dla każdego dokumentu wchodzącego w skład korpusu można określić dodatkowe informacje opisujące ten dokument, np. tytuł, autora, datę powstania. Informacji tych można potem używać przy przeszukiwaniu i analizowaniu korpusu.
Niniejsza instrukcja obsługi dotyczy wersji 0.3.
Aby uruchomić Smyrnę, należy dwukrotnie kliknąć plik smyrna-0.3.jar lub wydać z linii komend polecenie:
java -jar smyrna-0.3.jar
Spowoduje to uruchomienie przeglądarki i po chwili pokaże się ekran programu.
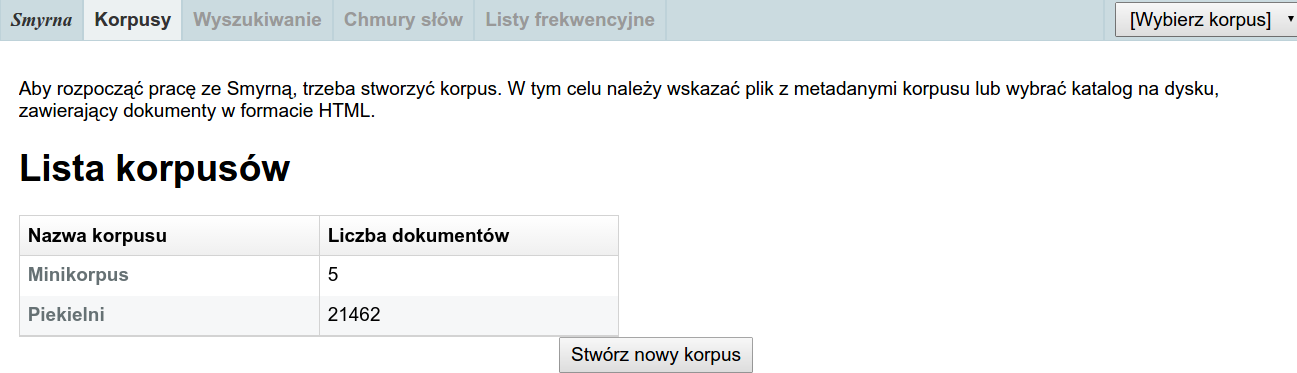
Lista korpusów
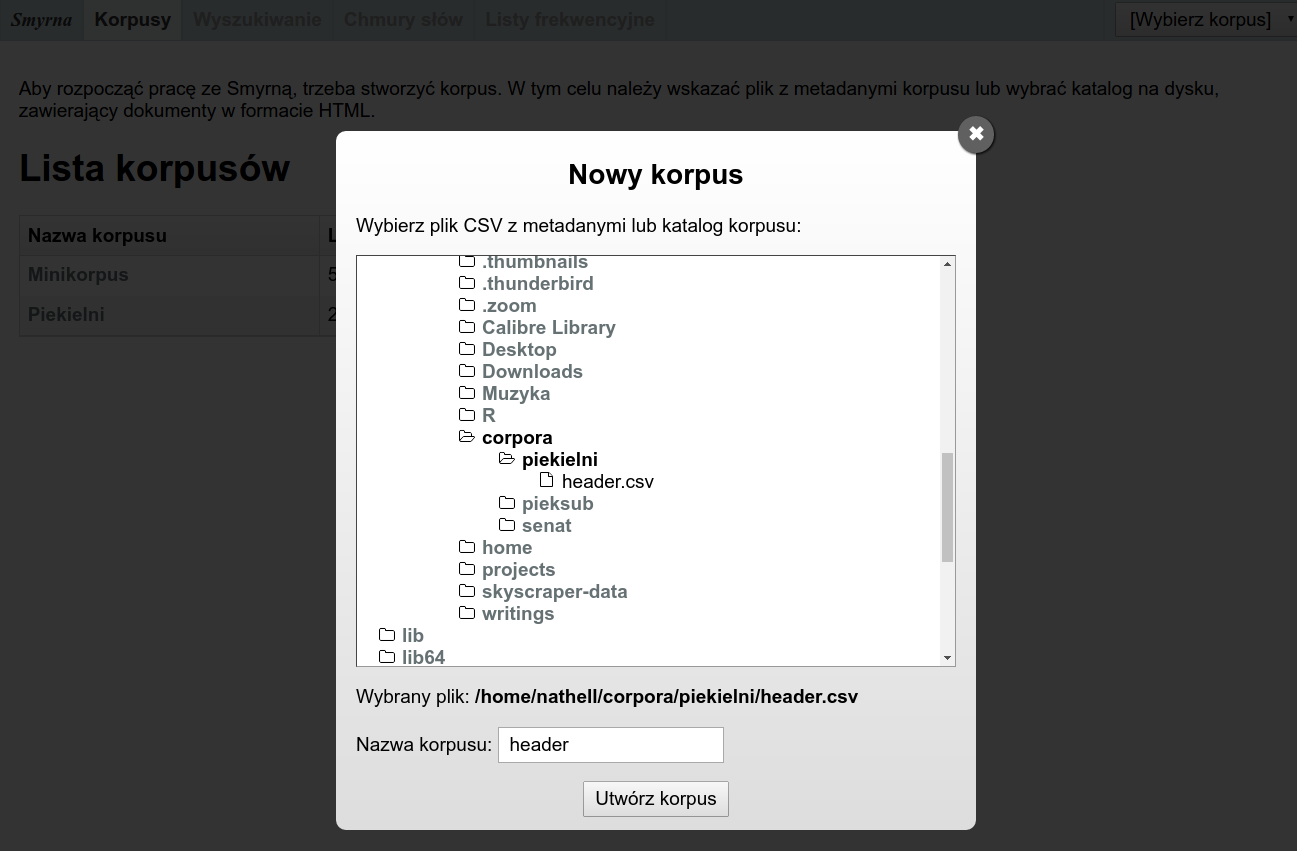
Pierwszą czynnością jest kliknięcie przycisku „Stwórz nowy korpus”. Pojawi się okno, w którym należy wybrać katalog zawierający pliki HTML lub plik z metadanymi w formacie CSV.
Jeśli zostanie wybrany plik CSV, to powinien on mieć nagłówek (pierwszy wiersz) zawierający kolumnę o nazwie file. W skład korpusu wejdą wszystkie pliki o nazwach umieszczonych w tej kolumnie. Pozostałe kolumny zostaną uznane za metadane opisujące poszczególne dokumenty.
Przykładowy plik CSV może mieć postać:
file,autor,tytuł
potop.html,Henryk Sienkiewicz,Potop
kordian.html,Juliusz Słowacki,KordianJeśli zostanie wybrany katalog, to Smyrna przeszuka go w poszukiwaniu plików HTML i jedyną metadaną każdego pliku będzie jego nazwa.
Tworzenie korpusu: wybór plików
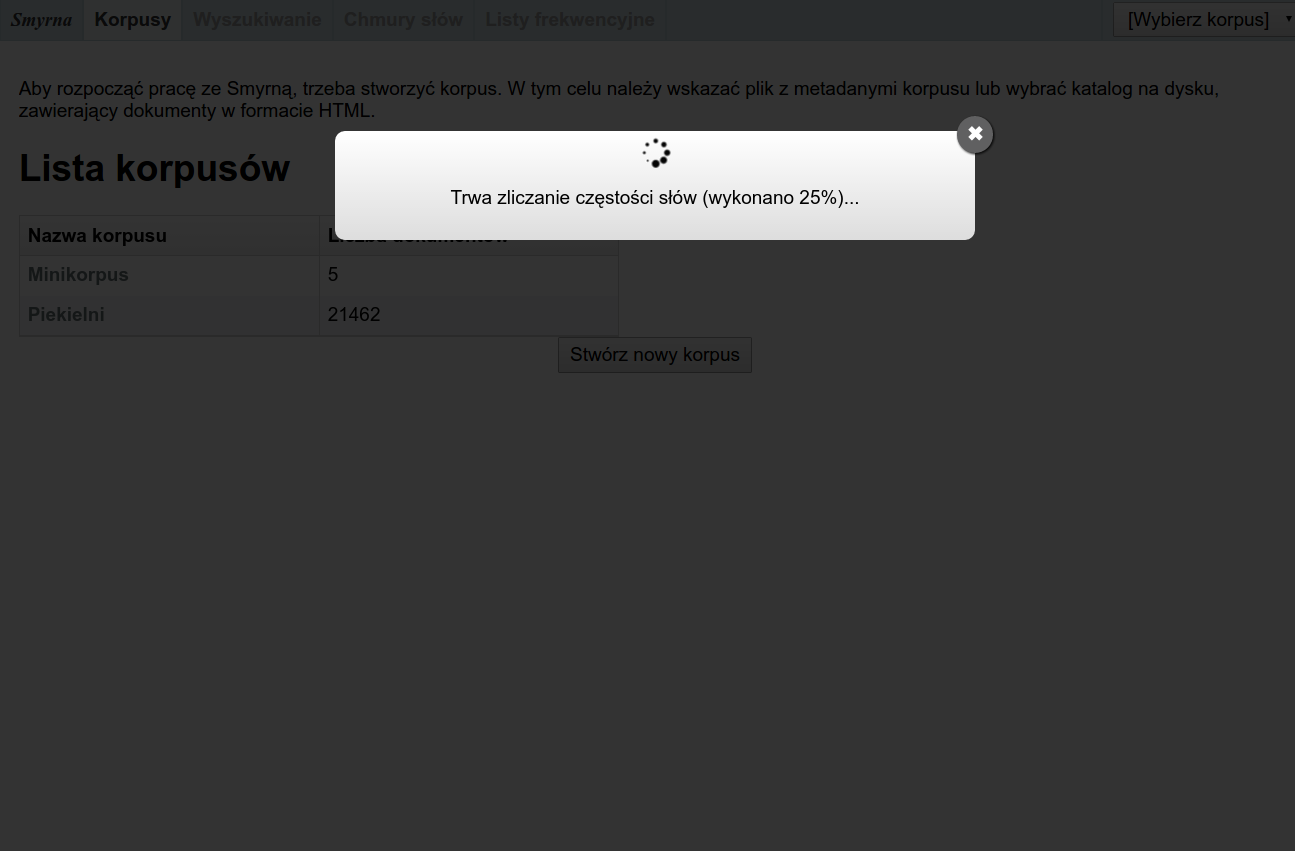
Po kliknięciu przycisku „Utwórz korpus” Smyrna przetworzy wszystkie dokumenty do postaci ułatwiającej przeszukiwanie. Proces ten może potrwać od kilku sekund do kilkunastu minut, w zależności od szybkości komputera i rozmiaru korpusu.
Tworzenie korpusu: w trakcie
Dla użytkowników poprzednich wersji: Smyrna 0.3 przechowuje każdy korpus jako pojedynczy plik w katalogu o nazwie
.smyrna(z kropką na początku) znajdującym się w katalogu domowym użytkownika (tzn. np.C:\Users\użytkownik\.smyrnaw systemie Windows). Inaczej niż w poprzednich wersjach, po utworzeniu korpusu źródłowe pliki.htmlnie są konieczne dla dalszej pracy ze Smyrną — plik korpusu zawiera wszystkie niezbędne informacje. Smyrna 0.3 nie obsługuje korpusów utworzonych za pomocą poprzednich wersji programu — należy zbudować je na nowo.
Po utworzeniu korpusu pojawi się on na liście (jeśli tak się nie stanie, należy odświeżyć stronę w przeglądarce).
Ze strony Smyrny można również pobrać przykładowe, gotowe do przeszukiwania korpusy.
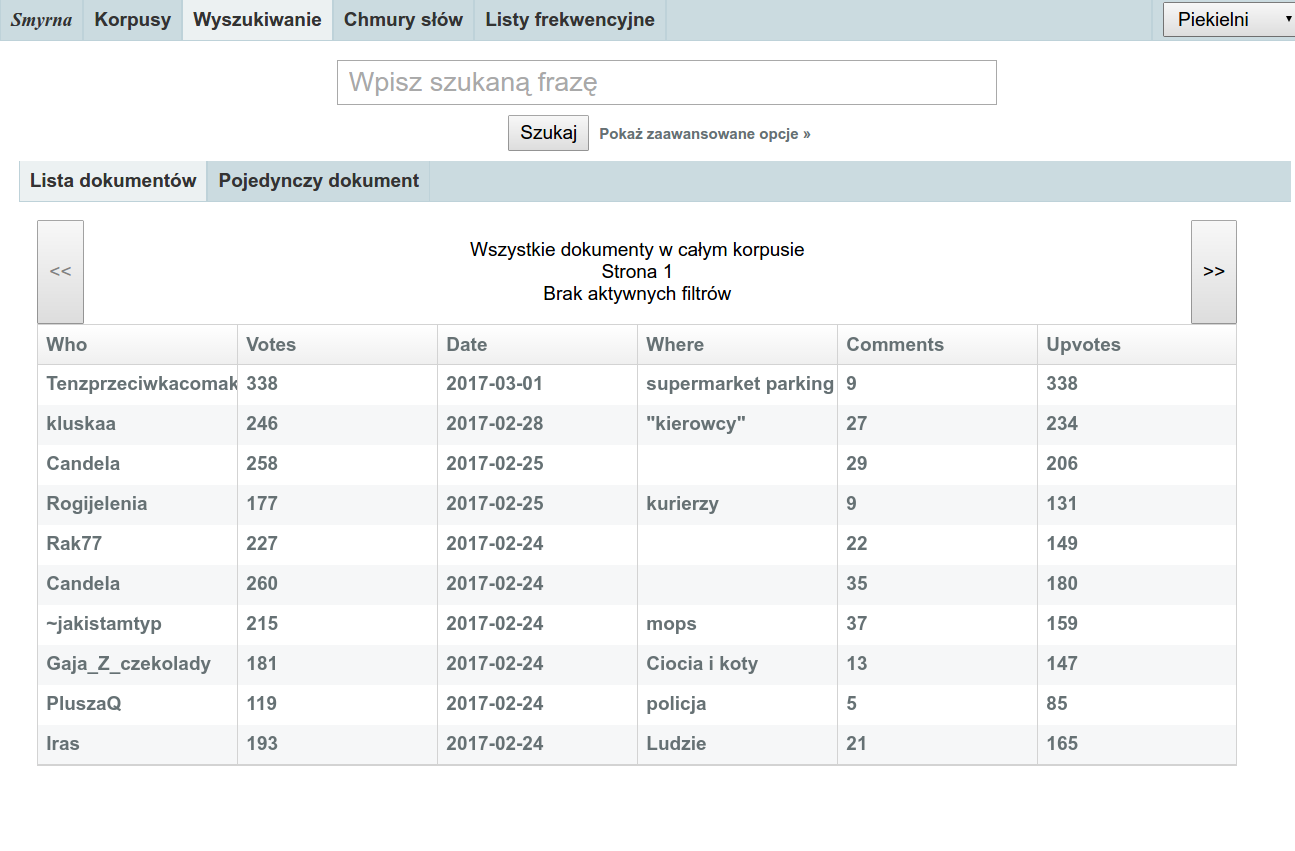
Po wybraniu korpusu pojawia się tabela z metadanymi wszystkich dokumentów w korpusie. Po wpisaniu frazy i kliknięciu „Szukaj” pojawią się tylko te dokumenty, w których ona występuje.
Lista dokumentów
Smyrna przeprowadza automatyczną analizę morfologiczną, tzn. wyszukiwanie słowa kot zwróci również dokumenty zawierające formy kota, kotami itp. To samo dotyczy fraz: zapytanie mały kot znajdzie dokumenty zawierające formy typu małego kota. Warto zwrócić uwagę, że wszystkie wpisywane słowa powinny być formami podstawowymi, a więc zamiast np. mała mysz należy zadać zapytanie mały mysz.
Inaczej niż w poprzednich wersjach Smyrny, w wersji 0.3 analiza morfologiczna jest wrażliwa na wielkość znaków (więc np. imiona lub skróty typu PKP należy wpisywać wielkimi literami).
Można również filtrować listę dokumentów według metadanych. Kliknięcie w tabeli nazwy dowolnej kolumny spowoduje wyświetlenie okna filtrowania. Na przykład kliknięcie kolumny Date (o ile taka występuje w korpusie) i wpisanie 2016 wyświetli tylko dokumenty z 2016 roku.
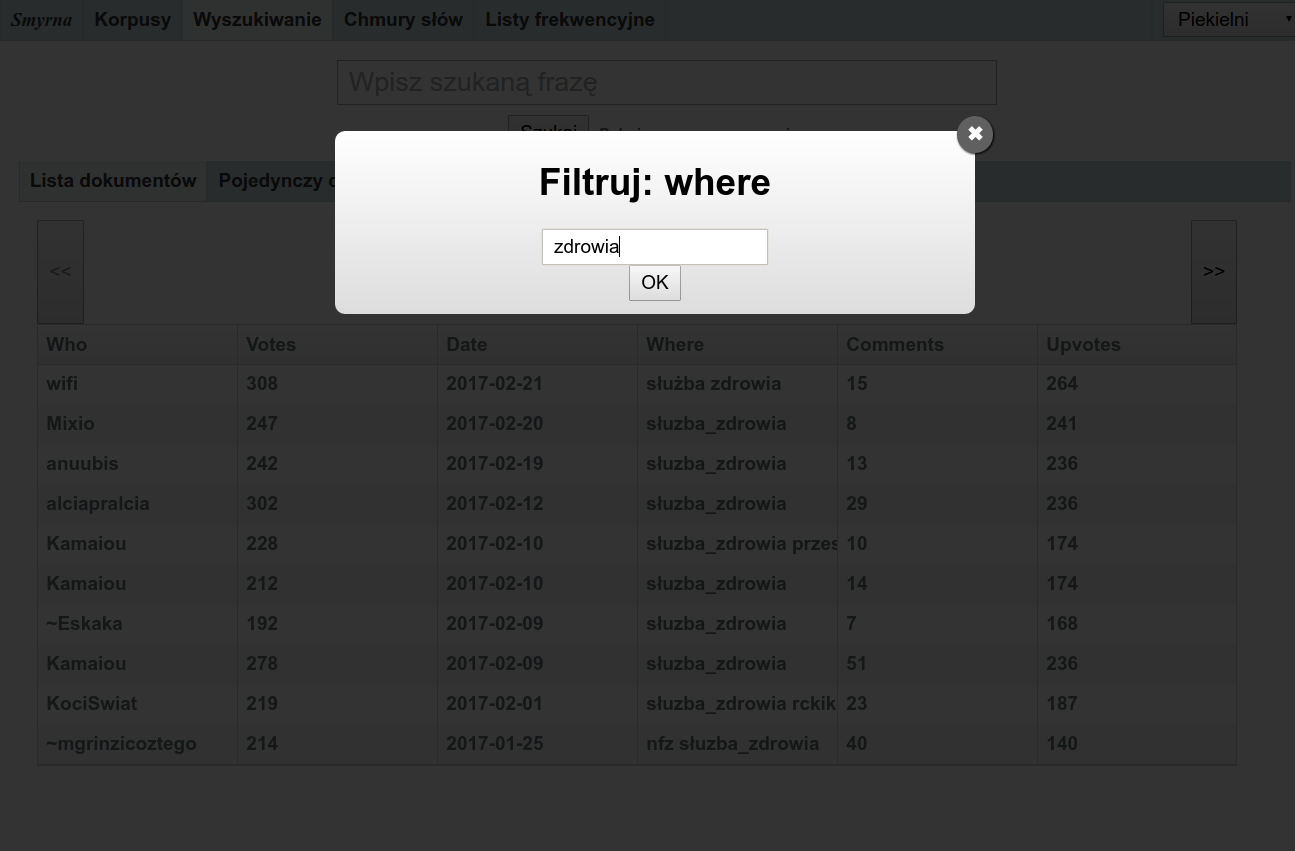
Filtrowanie według metadanych
Filtrowanie według metadanych można łączyć z wyszukiwaniem pełnotekstowym. Można więc np. wyszukać tylko dokumenty zawierające słowo kot z roku 2016.
Uwaga: Inaczej niż w wypadku wyszukiwania w treści dokumentów, dla metadanych nie jest wykonywana analiza morfologiczna. Jeżeli więc chce się znaleźć zarówno dokumenty oznaczone jako „zdrowie” lub „zdrowia”, należy wpisać zdrowi.
Kliknięcie w dowolny wiersz w tabeli metadanych spowoduje wyświetlenie odpowiadającego mu dokumentu w zakładce „Pojedynczy dokument”. Przyciskami << i >> można przechodzić do następnego lub poprzedniego dokumentu. Jeżeli została zadana fraza do wyszukania, to jej wystąpienia w wyświetlanym dokumencie będą podświetlone i pojawią się przyciski < i > służące do nawigowania między tymi wystąpieniami.
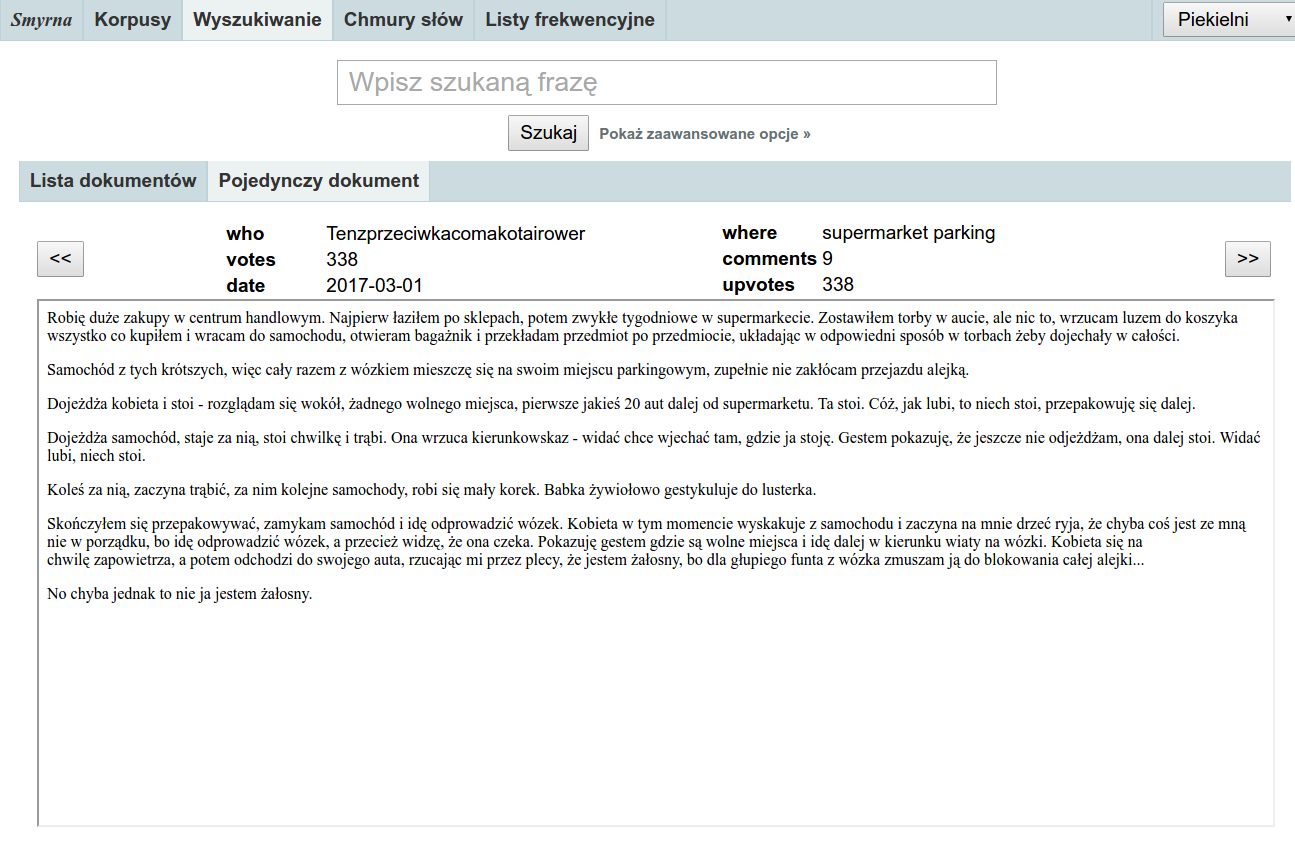
Wyświetlanie dokumentu
Obszarem jest zbiór dokumentów stanowiących wyniki wyszukiwania lub filtrowania – inaczej mówiąc, dowolny podzbiór dokumentów w korpusie. Może być nim w szczególności cały korpus.
Obszarowi można nadać nazwę i zapamiętać go. W tym celu należy kliknąć „Pokaż zaawansowane opcje”, po czym kliknąć przycisk „Utwórz obszar”. Pojawi się okienko, w którym Smyrna poprosi o nadanie nazwy obszarowi.
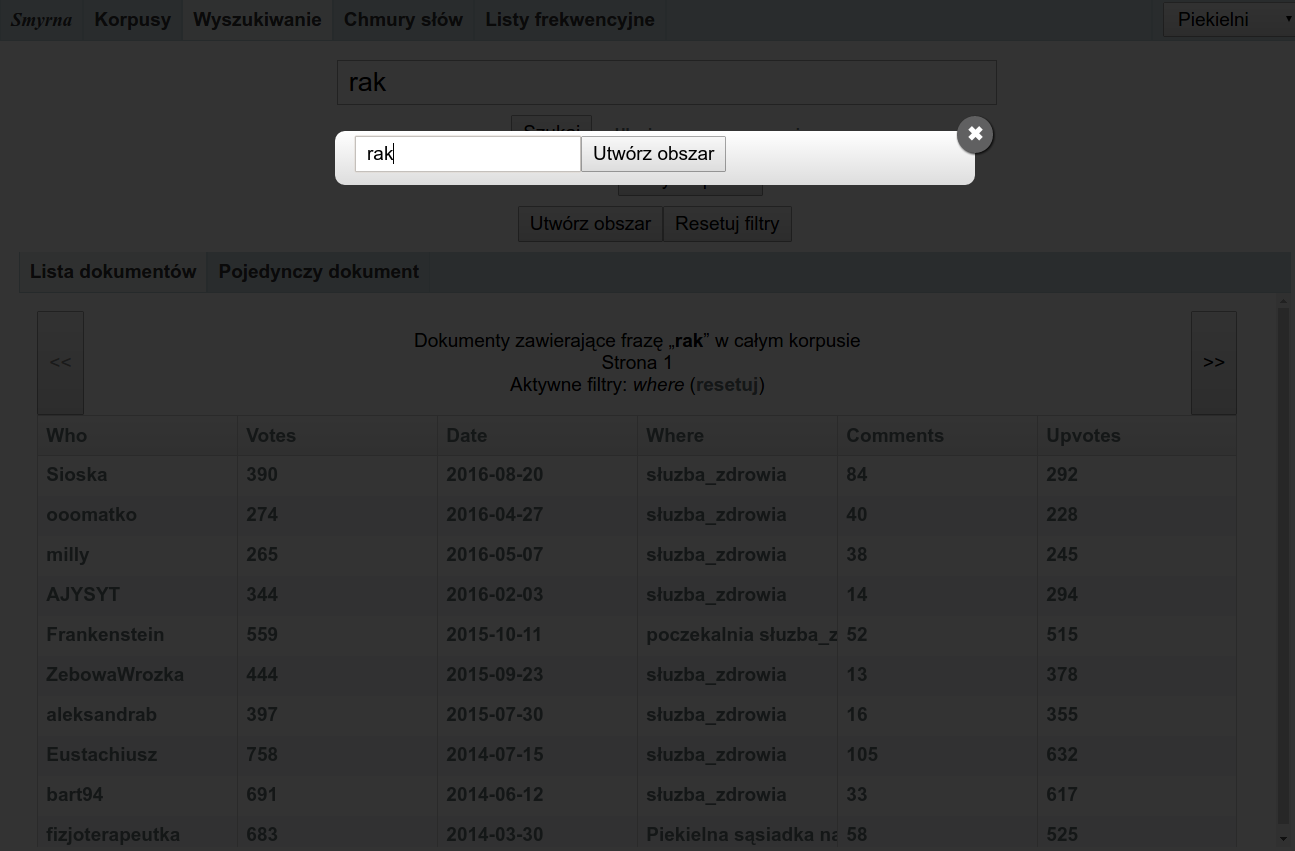
Tworzenie obszaru
Tak zdefiniowany obszar można poddawać różnym analizom, a także przeszukiwać podobnie jak cały korpus. Można np. zdefiniować obszar „kot”, składający się z dokumentów zawierających frazę kot, po czym w tym obszarze wyszukać frazę pies. Spowoduje to wyświetlenie dokumentów zawierających zarówno frazę kot, jak i pies.
Zakładka „Chmury słów” pozwala na wygenerowanie jednym kliknięciem zestawu słów charakterystycznych dla danego obszaru w porównaniu do całego korpusu. Wystarczy wybrać uprzednio utworzony obszar i kliknąć „Pokaż”.

Chmury słów
Dane słowo jest tym większe na chmurze, im częściej statystycznie pojawia się ono w badanym obszarze w porównaniu do całego korpusu. Statystyką używaną do generowania chmur słów jest log-likelihood.
W zakładce „Listy frekwencyjne” można sprawdzić, jakie słowa (dokładniej: formy podstawowe leksemów) pojawiają się najczęściej w korpusie bądź w zadanym obszarze. Po wybraniu obszaru i kliknięciu „Pokaż” Smyrna wygeneruje listę frekwencyjną, którą można przeglądać w tabeli wewnątrz programu albo wyeksportować do formatu CSV, obsługiwanego np. przez program Excel.
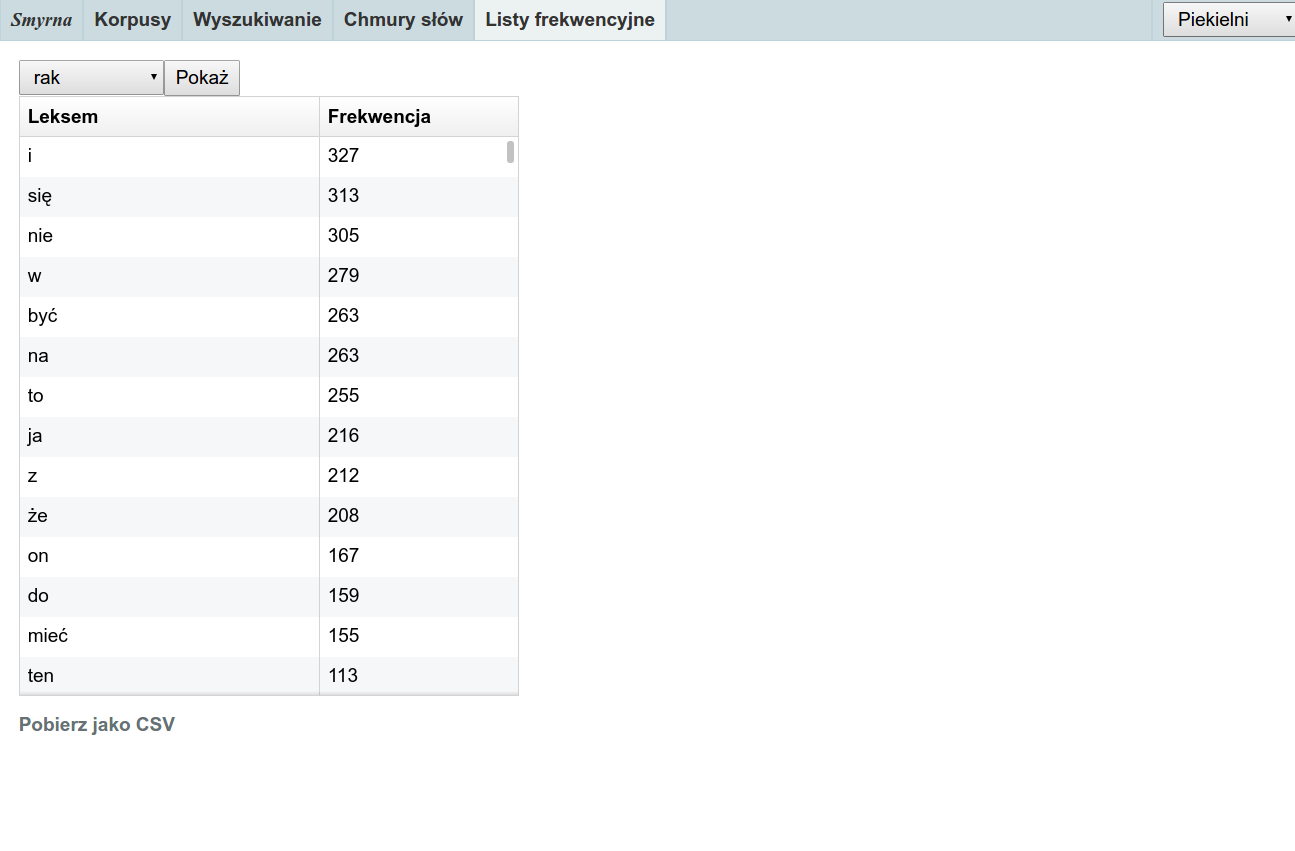
Listy frekwencyjne
P: Jak zakończyć działanie programu Smyrna?
O: Normalnie nie ma takiej potrzeby, wystarczy zamknąć okno przeglądarki. Smyrna będzie nadal działać w tle i można ponownie uruchomić interfejs wchodząc na adres http://localhost:6510. Jeśli zachodzi konieczność zwolnienia zasobów systemowych, należy użyć systemowego menedżera procesów (Windows: Ctrl-Alt-Del) i zamknąć program java.
P: Jak zapisać chmurę słów w postaci obrazka?
O: Smyrna nie udostępnia wprost takiej opcji, ale można wykonać zrzut ekranu. Najprościej jest użyć wtyczki do przeglądarki, np. Awesome Screenshot dla Chrome.